
Hybrid search: the decision I didn't know I needed in my agent
TL;DR: While building a conversational agent for a travel agency, I discovered that hybrid search, merging semantic and lexical search results, noticeably improved my RAG system.
When you read about semantic search, hybrid search, and full text search, you almost always find generic technical examples: documents, recipes, products, or support links. They help explain the theory, but they do not explain the real cases that appear when all of that lives inside a conversational agent.
So imagine we are building an agent for a travel agency that needs to be powered by a RAG. The initial idea seemed good enough: turn the travel plan information into embeddings, connect it to a RAG-style flow, and let the agent answer from there.
On paper, it sounded good. In practice, it was not enough.
The problem was not retrieving information. The problem was retrieving the right information for the moment in the conversation.
It is not the same when a person asks:
- “getaways somewhere warm” - Ambiguous question
- “something adventurous near Denver” - Exploratory question
- “what about the Yosemite itinerary?” - Follow-up question
All three are valid questions, but they require different things: some need interpretation, others need textual precision. At first, I thought that meant choosing between strategies. After testing it in practice, the conclusion was different: I needed a single search that understood intent and respected the exact text at the same time. That is exactly what hybrid search does.
What is hybrid search?
Before getting into what each search contributes, it is worth understanding the general idea. Hybrid search is not a new technique: it is combining two searches that already exist and running them in parallel over the same query.
- Lexical search (full text search): looks for exact keyword matches. It is precise but rigid.
- Semantic search (vector search): looks for meaning and intent, even when the words do not match. It is flexible but sometimes imprecise.
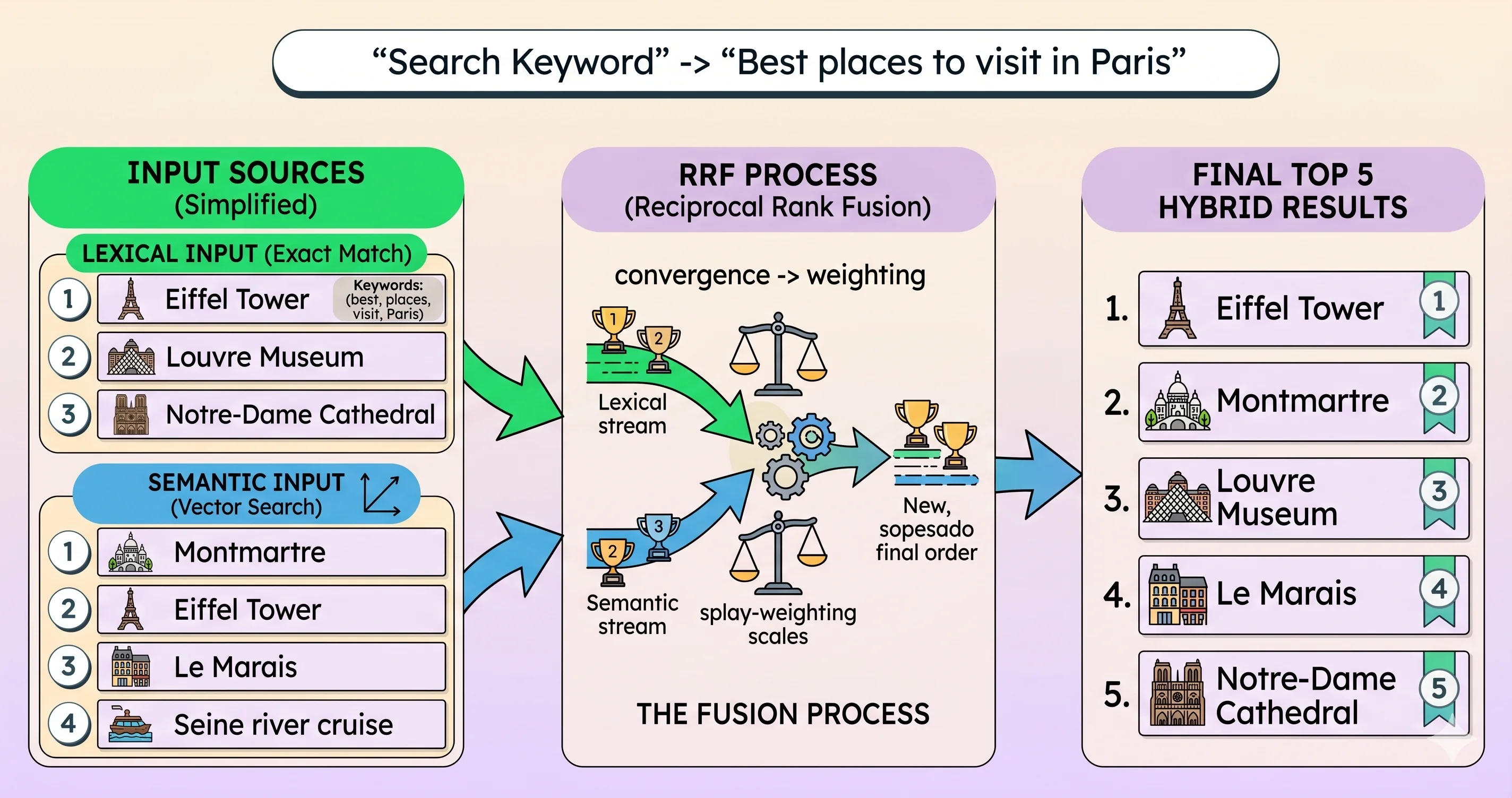
The challenge is that each one returns its own ranking with scores that are not comparable to each other. That is where Reciprocal Rank Fusion (RRF) comes in: instead of mixing the raw scores, it takes the position of each result in both lists and produces a single final ranking.
In the example from the image, the query “Best places to visit in Paris” is executed through both paths. Lexical search ranks the Eiffel Tower first because of exact word matches; semantic search ranks Montmartre first because of intent similarity. RRF combines both rankings, adding the contribution of each list according to position, and reorders everything into a final list where the Eiffel Tower ends up on top because it appears in a strong position in both searches at the same time.
That is the core idea: a result that convinces both layers rises more strongly. With that clear, let’s look at what each layer contributes on its own.
What the semantic layer contributes: semantic search
Semantic search does not answer “do these words appear?” but rather “what content is similar in intent to this query?”. That is key because people almost never speak the way the site is written: they use abbreviations, slang, vague phrases, or they misremember the name of a travel plan.
That is why the semantic layer wins when the main job is to understand: intent-based queries (“getaways somewhere warm”), exploratory queries (“something adventurous near Denver”), or follow-up questions where the query already comes contextualized by the conversation history (“what about the itinerary?” => “itinerary for the Yosemite plan”). In all those cases, it connects intent with the right content even when the words do not literally match.
The problem appears when the conversation stops being ambiguous. If the user already knows which plan they are interested in and asks for something specific (“tell me in detail the itinerary for Yosemite”), a purely semantic search can bring back reasonable results but not the most precise ones, because words like “itinerary” or “price” appear in many plans. Understanding intent still matters, but it is no longer enough: the answer also has to be anchored to the right text.
What the lexical layer contributes: full text search
Full text search answers a different question: “where do these words or close variations appear?”. It is a more classic and deterministic search that rewards textual matching, and it is useful when the user knows the exact name of the plan, uses terms that literally exist in the content, or is looking for something very specific.
The problem is that, inside an agent, I do not want to depend only on that either: if the user writes with slang, misremembers the name, or phrases the idea more naturally, full text search falls short very quickly. That is why it makes no sense to choose between the semantic layer and the lexical layer. The solution is to always combine them in a single hybrid search.
The solution: hybrid search as the default
Hybrid search is not a middle ground or an option for special cases. It is the default: it runs both layers in parallel and merges their results into a single weighted list.
It helped me cover the space between two opposite failures:
- the rigidity of full text search
- the possible semantic drift of semantic search
Put simply: there are queries where meaning matters, but it also matters a lot that certain words are literally present. Instead of deciding which one matters more depending on the question, hybrid search lets the final ranking resolve it.
The underlying idea is simple:
- run a text search
- run a semantic search
- combine both rankings to produce a more stable final ranking
It is not about choosing one and discarding the other. It is about adding evidence on every query.
If a result appears in a strong position both because of textual matching and semantic closeness, it rises more strongly in the final ranking. And that, for a conversational agent, is very valuable because it reduces two very common errors:
- bringing something semantically close, but not specific enough
- missing the right answer because the person did not write the exact phrase
The tests: semantic vs hybrid vs full text
To validate it, I built a view that runs the same query through all three paths, semantic, hybrid, and full text, and compares the results side by side.
In an exploratory query like “recommended destination plans”, full text comes back empty: there is no literal match for those words in the content. Semantic search does understand the intent and brings relevant plans, and hybrid ends up relying on that semantic signal to return a good ranking. Here the lexical layer does not contribute, but it also does not get in the way.
In a precise query like “Grand Canyon South Rim”, the picture changes: all three paths return results, but hybrid is the only one that combines the best of both. It merges the plan that full text finds through exact textual matching with the one semantic search finds through meaning similarity, and reorders them with RRF so that the ones that rank well in both lists rise to the top.
In my tests, hybrid search produced better results than semantic search alone in every scenario. I did not find a case where it was worth using only one layer.
The math behind the magic: RRF
Here is the detail that makes everything work. Semantic search and text search do not produce comparable scores: one relies on vector similarity, values between 0 and 1, and the other on lexical relevance, a number with no upper bound. Adding those scores directly would be like adding meters and kilograms or apples and oranges.
Reciprocal Rank Fusion (RRF) avoids that problem with an elegant idea: it ignores the score value and keeps only the position of each document in each list. The final score of a document is the sum of its contribution in each ranking:
Where is the document, is the position it occupies in ranking (semantic or lexical), and is a smoothing constant (a typical value is ). The intuition is straightforward: being in first position contributes , second contributes , and so on; the lower it appears, the less it adds.
What is powerful is what happens when a document appears in both lists: its two contributions accumulate and push it upward. A result that convinces both the semantic and the lexical layer ends up beating another one that only stood out in one. And because everything is measured in positions, there is never any need to force an artificial equivalence between scores that mean different things.
The hidden cost: keeping RAG alive
When people talk about hybrid search, it is easy to focus only on the nice part of the final ranking. But the real cost of any RAG is not in the search itself: it is in keeping the system alive. The knowledge base is not something you index once and forget; you have to keep it synchronized with reality.
Every time a travel plan changes, two things have to be rebuilt at the same time. On one hand, you need to regenerate the embeddings so the semantic layer keeps understanding the new content. On the other hand, you have to recalculate the terms or tokens that feed lexical search, which normally implies a function that extracts and normalizes the keywords from the text. It is not a single indexing process: it is several layers that have to move together every time the content changes.
That pipeline, parsing, chunking, generating embeddings, tokenizing for keywords, indexing in parallel, fusing with RRF, and reranking, is exactly the one Cloudflare describes when explaining its AI Search agent primitive. Because maintaining it is so complex, many companies already offer it packaged as RAG as a service: from the outside it looks like a single API, but underneath it is exactly this.
In my case, since I use Supabase, I did not have to build that whole pipeline from scratch. I supported it by following their official hybrid search guide, which combines tsvector (full text search) and pgvector (semantic search) in a single SQL function and solves the fusion with RRF directly in Postgres.
How I brought it into the conversational agent
With search solved, the agent exposes a single retrieval tool: hybrid search. The agent does not decide whether to use semantic or lexical search; it simply passes the query and the tool returns the most appropriate results according to the context, already merged with RRF and ranked. That way, the agent focuses on answering, not on choosing how to search.
In practice, with a framework like Google ADK, it is enough to expose that search as just another tool for the agent:
root_agent = Agent(
model="gemini-pro-latest",
name="amaru",
description="Your travel agent.",
mode="chat",
instruction='Your instructions here',
tools=[
search_context,
],
)Here search_context is the tool that runs the hybrid search query against the knowledge base and returns the already ranked context. The agent decides when to call it, passes the query, contextualized with the history when needed, and answers from that context. There is no “which strategy should I use?” logic: that decision already lives inside the search, and the agent just consumes the result.
In the Amaru agent it is already integrated. With an exploratory query like “getaways somewhere warm”, the agent calls search_context, retrieves relevant plans, and answers with concrete options without the user having given an exact name:
With a more precise query like “grand canyon south rim tours”, the flow is the same: one tool only, but the returned context already anchors the answer to the correct plan and the agent responds with specific routes and itineraries:
Conclusion
Building a conversational agent with RAG taught me that the challenge is not retrieving information, but retrieving the right information at each moment in the conversation. Sometimes the user explores with vague language; at other times, they already know the plan and ask for a specific detail. That duality is not solved by choosing between semantic search and full text search: it is solved by always combining them and letting RRF decide how much each layer should weigh for the query.
The tests confirmed it. In exploratory queries, hybrid relies on semantics without the lexical layer getting in the way. In precise queries, it merges textual matching and meaning similarity to push the right result upward. In no scenario did I find a case where it was worth using only one layer.
The real cost is on the other side: keeping the RAG alive, regenerating embeddings, recalculating keywords, and synchronizing indexes every time the content changes. But once that pipeline is solved, integrating search into the agent is straightforward: one tool, one query, already ranked context. Amaru shows it in every conversation.
Hybrid search stopped being a documentation recommendation and became the default in my agent. Not because it is the most sophisticated technique, but because it is the one that best survives the way people speak when they discover, compare, and go deeper into a plan.