
Hybrid search: la decisión que no sabía que necesitaba en mi agente
TL;DR: Construyendo un agente conversacional para una agencia de viajes, descubrí que hybrid search —fusionar los resultados de la búsqueda semántica y la léxica— mejoró notablemente mi sistema RAG.
Cuando uno lee sobre semantic search, hybrid search y full text search, casi siempre encuentra ejemplos tecnicos genéricos: documentos, recetas, productos o links a support. Sirven para entender la teoría, pero no explican los casos reales que aparecen cuando todo eso vive dentro de un agente conversacional.
Entonces imaginemos que estamos construyendo un agente para una agencia de viajes que debe alimentarse de un RAG. La idea inicial parecía suficiente: convertir la información de los planes turísticos en embeddings, conectarla a un flujo tipo RAG y dejar que el agente respondiera desde ahí.
Sobre el papel sonaba bien. En la práctica, no alcanzaba.
El problema no era recuperar información. El problema era recuperar la información correcta según el momento de la conversación.
No es lo mismo que una persona pregunte:
- “planes pa tierra caliente” - Pregunta Ambigua
- “algo de aventura cerca de Bogotá” - Pregunta exploratoria
- “¿y el itinerario de Guatavita?” - Pregunta de seguimiento
Las tres son preguntas válidas, pero exigen cosas distintas: unas necesitan interpretación, otras precisión textual. Al principio pensé que eso significaba elegir entre estrategias. Después de probar en la práctica, la conclusión fue otra: necesitaba una sola búsqueda que entendiera intención y respetara el texto exacto al mismo tiempo. Eso es exactamente lo que hace hybrid search.
¿Qué es hybrid search?
Antes de entrar en el detalle de qué aporta cada búsqueda, vale la pena entender la idea general. Hybrid search no es una técnica nueva: es combinar dos búsquedas que ya existen y ejecutarlas en paralelo sobre la misma consulta.
- Búsqueda léxica (full text search): busca coincidencias exactas de palabras clave. Es precisa pero rígida.
- Búsqueda semántica (vector search): busca por significado e intención, aunque las palabras no coincidan. Es flexible pero a veces imprecisa.
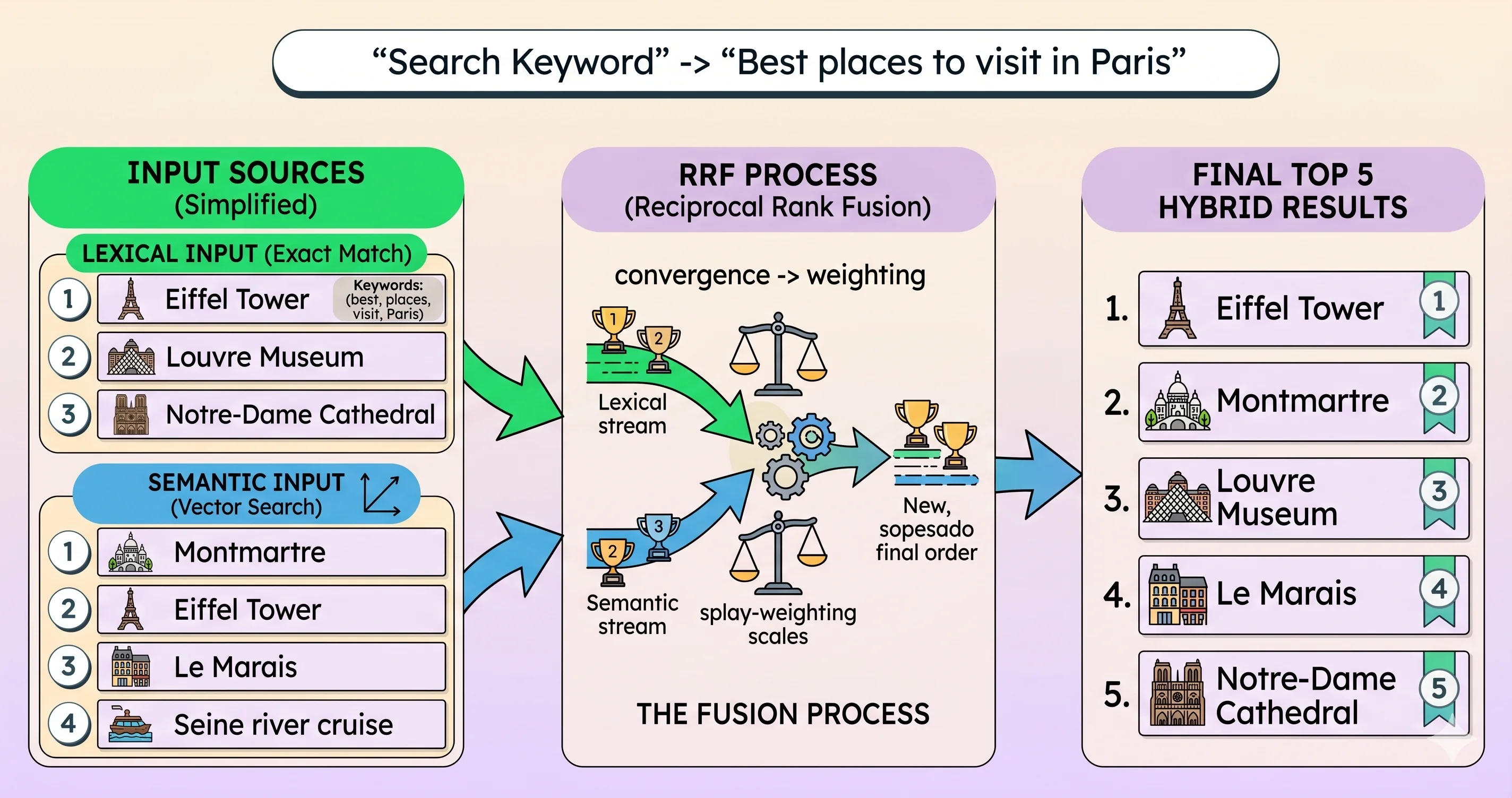
El reto es que cada una entrega su propio ranking con puntajes que no son comparables entre sí. Ahí entra Reciprocal Rank Fusion (RRF): en lugar de mezclar los scores crudos, toma la posición de cada resultado en ambas listas y produce un único ranking final.
En el ejemplo de la imagen, la consulta “Best places to visit in Paris” se ejecuta por las dos vías. La búsqueda léxica posiciona primero la Eiffel Tower por coincidencia exacta de palabras; la semántica posiciona primero Montmartre por cercanía de intención. RRF combina ambos rankeos —sumando el aporte de cada lista según la posición— y reordena todo en una lista final donde la Eiffel Tower queda arriba porque aparece bien posicionada en las dos búsquedas a la vez.
Esa es la idea de fondo: un resultado que convence a ambas capas sube con más fuerza. Con esto claro, veamos qué aporta cada capa por separado.
Lo que aporta la capa semántica: semantic search
La búsqueda semántica no responde “¿aparecen estas palabras?”, sino “¿qué contenido se parece en intención a esta consulta?”. Eso es clave porque las personas casi nunca hablan como está escrito el sitio: usan abreviaciones, jerga, frases vagas o recuerdan mal el nombre de un plan.
Por eso la capa semántica gana cuando el trabajo principal es entender: consultas por intención (“planes pa tierra caliente”), consultas exploratorias (“algo de aventura cerca de Bogotá”) o preguntas de seguimiento donde la consulta ya viene contextualizada con el historial (“¿y el itinerario?” => “itinerario del plan de Guatavita”). En todos esos casos conecta la intención con el contenido correcto aunque las palabras no coincidan literalmente.
El problema aparece cuando la conversación deja de ser ambigua. Si el usuario ya sabe qué plan le interesa y pide algo puntual (“dime en detalle el itinerario para Guatavita”), una búsqueda puramente semántica puede traer resultados razonables pero no los más precisos, porque palabras como “itinerario” o “precio” aparecen en muchos planes. Entender la intención sigue importando, pero ya no basta: también hay que anclar la respuesta al texto correcto.
Lo que aporta la capa léxica: full text search
Full text search responde una pregunta distinta: “¿dónde aparecen estas palabras o variaciones cercanas?”. Es una búsqueda más clásica y determinista que premia la coincidencia textual, y resulta útil cuando el usuario conoce el nombre exacto del plan, usa términos que existen literalmente en el contenido o busca algo muy puntual.
El problema es que, dentro de un agente, tampoco quiero depender solo de eso: si el usuario escribe con jerga, recuerda mal el nombre o formula la idea de forma más natural, full text search se queda corto muy rápido. Por eso no tiene sentido elegir entre capa semántica y capa léxica. La solución es combinarlas siempre en una sola búsqueda híbrida.
La solución: hybrid search como default
Hybrid search no es un punto medio ni una opción para casos especiales. Es el default: ejecuta ambas capas en paralelo y fusiona sus resultados en una sola lista ponderada.
Me ayudó a cubrir el espacio que queda entre dos fallas opuestas:
- la rigidez de full text search
- la posible deriva semántica de semantic search
Dicho simple: hay consultas donde importa el significado, pero también importa muchísimo que ciertas palabras estén presentes de forma literal. En lugar de decidir cuál pesa más según la pregunta, hybrid search deja que el ranking final lo resuelva.
La idea de fondo es sencilla:
- se ejecuta una búsqueda por texto
- se ejecuta una búsqueda semántica
- se combinan ambos rankeos para producir un ranking final más estable
No se trata de escoger una y descartar la otra. Se trata de sumar evidencia en cada consulta.
Si un resultado aparece bien posicionado tanto por coincidencia textual como por cercanía semántica, sube con más fuerza en el ranking final. Y eso, para un agente conversacional, es muy valioso porque reduce dos errores muy comunes:
- traer algo semánticamente cercano, pero no lo suficientemente específico
- perder la respuesta correcta porque la persona no escribió la frase exacta
Las pruebas: semantic vs hybrid vs full text
Para comprobarlo armé una vista que ejecuta la misma consulta por las tres vías —semantic, hybrid y full text— y compara los resultados lado a lado.
En una consulta exploratoria como “planes destinos recomendados”, full text se queda en blanco: no hay coincidencia literal de esas palabras en el contenido. La búsqueda semántica sí entiende la intención y trae planes relevantes, y hybrid termina apoyándose en esa señal semántica para devolver un buen ranking. Aquí la capa léxica no aporta, pero tampoco estorba.
En una consulta puntual como “Cumbre Nevado del Tolima” cambia el panorama: las tres vías devuelven resultados, pero hybrid es la única que combina lo mejor de ambas. Fusiona el plan que full text encuentra por coincidencia textual exacta con el que la semántica encuentra por cercanía de significado, y los reordena con RRF para dejar arriba los que aparecen bien posicionados en las dos listas.
En mis pruebas, hybrid search dio resultados mejores que semantic search sola en todos los escenarios. No encontré un caso donde valiera la pena usar solo una capa.
La magia matemática detrás: RRF
Aquí está el detalle que hace que todo funcione. La búsqueda semántica y la búsqueda por texto no producen puntajes comparables entre sí: una se apoya en similitud vectorial (valores entre 0 y 1) y la otra en relevancia léxica (un número sin límite superior). Sumar esos scores directamente sería como sumar metros con kilos o peras con manzanas.
Reciprocal Rank Fusion (RRF) esquiva ese problema con una idea elegante: ignora el valor del score y se queda solo con la posición de cada documento en cada lista. El puntaje final de un documento es la suma de su aporte en cada ranking:
Donde es el documento, es la posición que ocupa en el ranking (semántico o léxico) y es una constante de suavizado (un valor típico es ). La intuición es directa: estar en la primera posición aporta , la segunda aporta , y así sucesivamente; mientras más abajo, menos suma.
Lo poderoso es lo que pasa cuando un documento aparece en ambas listas: sus dos aportes se acumulan y lo empujan hacia arriba. Un resultado que convence tanto a la capa semántica como a la léxica termina ganándole a otro que solo destacó en una. Y como todo se mide en posiciones, nunca hay que forzar una equivalencia artificial entre puntajes que significan cosas distintas.
El costo oculto: mantener vivo el RAG
Cuando uno habla de hybrid search es fácil enfocarse solo en la parte bonita del ranking final. Pero el verdadero costo de cualquier RAG no está en la búsqueda: está en mantener el sistema vivo. La base de conocimiento no es algo que se indexa una vez y se olvida; hay que mantenerla sincronizada con la realidad.
Cada vez que cambia un plan turístico hay que rehacer dos cosas a la vez. Por un lado, regenerar los embeddings para que la capa semántica siga entendiendo el contenido nuevo. Por otro, recalcular los términos (tokens) que alimentan la búsqueda léxica, lo que normalmente implica una función que extrae y normaliza las palabras clave del texto. No es una sola indexación: son varias capas que deben moverse juntas cada vez que el contenido cambia.
Ese pipeline —parsear, chunkear, generar embeddings, tokenizar para keywords, indexar en paralelo, fusionar con RRF y rerankear— es exactamente el que describe Cloudflare cuando explica su AI Search agent primitive. Por lo complejo que es sostenerlo, muchas empresas ya lo ofrecen empaquetado como RAG as a service: por fuera parece una sola API, pero por detrás es justo esto.
En mi caso, como uso Supabase, no tuve que montar toda esa tubería desde cero. Lo soporté siguiendo su guía oficial de hybrid search, que combina tsvector (full text search) y pgvector (semantic search) en una sola función SQL y resuelve la fusión con RRF directamente en Postgres.
Cómo lo llevé al agente conversacional
Con la búsqueda resuelta, el agente expone una sola tool de recuperación: hybrid search. El agente no decide si usar semántica o léxica; simplemente le pasa la consulta y la tool devuelve los resultados más apropiados según el contexto, ya fusionados con RRF y rankeados. Así el agente se concentra en responder, no en elegir cómo buscar.
En la práctica, con un framework como Google ADK basta con exponer esa búsqueda como una tool más del agente:
root_agent = Agent(
model="gemini-pro-latest",
name="amaru",
description="Your travel agent.",
mode="chat",
instruction='Your instructions here',
tools=[
search_context,
],
)Aquí search_context es la tool que ejecuta la consulta de hybrid search contra la base de conocimiento y devuelve el contexto ya rankeado. El agente decide cuándo llamarla, le pasa la consulta (contextualizada con el historial cuando hace falta) y responde a partir de ese contexto. No hay lógica de “qué estrategia usar”: esa decisión ya vive dentro de la búsqueda, y el agente solo consume el resultado.
En el agente Amaru ya se ve integrada. Con una consulta exploratoria como “planes a tierra caliente”, el agente invoca search_context, recupera planes relevantes y responde con opciones concretas sin que el usuario haya dado un nombre exacto:
Con una consulta más puntual como “planes para cumbre nevado tolima”, el flujo es el mismo: una sola tool, pero el contexto devuelto ya ancla al plan correcto y el agente responde con rutas e itinerarios específicos:
Conclusión
Construir un agente conversacional con RAG me enseñó que el reto no es recuperar información, sino recuperar la correcta en cada momento de la conversación. A veces el usuario explora con lenguaje vago; otras, ya sabe el plan y pide un detalle puntual. Esa dualidad no se resuelve eligiendo entre semantic search o full text search: se resuelve combinándolas siempre y dejando que RRF decida cuánto pesa cada capa según la consulta.
Las pruebas lo confirmaron. En consultas exploratorias, hybrid se apoya en la semántica sin que la capa léxica estorbe. En consultas puntuales, fusiona coincidencia textual y cercanía de significado para subir el resultado correcto. En ningún escenario encontré un caso donde valiera la pena usar solo una capa.
El costo real está del otro lado: mantener vivo el RAG —regenerar embeddings, recalcular keywords, sincronizar índices cada vez que cambia el contenido—. Pero una vez resuelta esa tubería, integrar la búsqueda en el agente es directo: una tool, una consulta, contexto ya rankeado. Amaru lo demuestra en cada conversación.
Hybrid search dejó de ser una recomendación de documentación y se volvió el default de mi agente. No porque sea la técnica más sofisticada, sino porque es la que mejor sobrevive a cómo hablan las personas cuando descubren, comparan y profundizan en un plan.